portfolio

Skills: Python, Docker, Apache Airflow, LlamaIndex, AWS, PostgreSQL, Google Cloud Storage, End-to-end ML pipeline, RAG (LLMs), Web Scraping, MLOps
GiHub RAG Chatbot
The GitHub Ideation Bot is a tool designed to extract project ideas from `README.md` files of popular GitHub repositories in data science and machine learning. The pipeline is managed using Apache Airflow, which automates the process of scraping these files and generating embeddings with LlamaIndex and OpenAI's GPT-3.5 model.
The system is fully containerized using Docker and hosted on an AWS EC2 instance, with Streamlit front-end and PostgreSQL backend. The architecture is designed for easy maintenance, allowing each component to be independently managed and updated. This project is designed to be scalable and reproducible for deploying machine learning pipelines in cloud environments.
learn more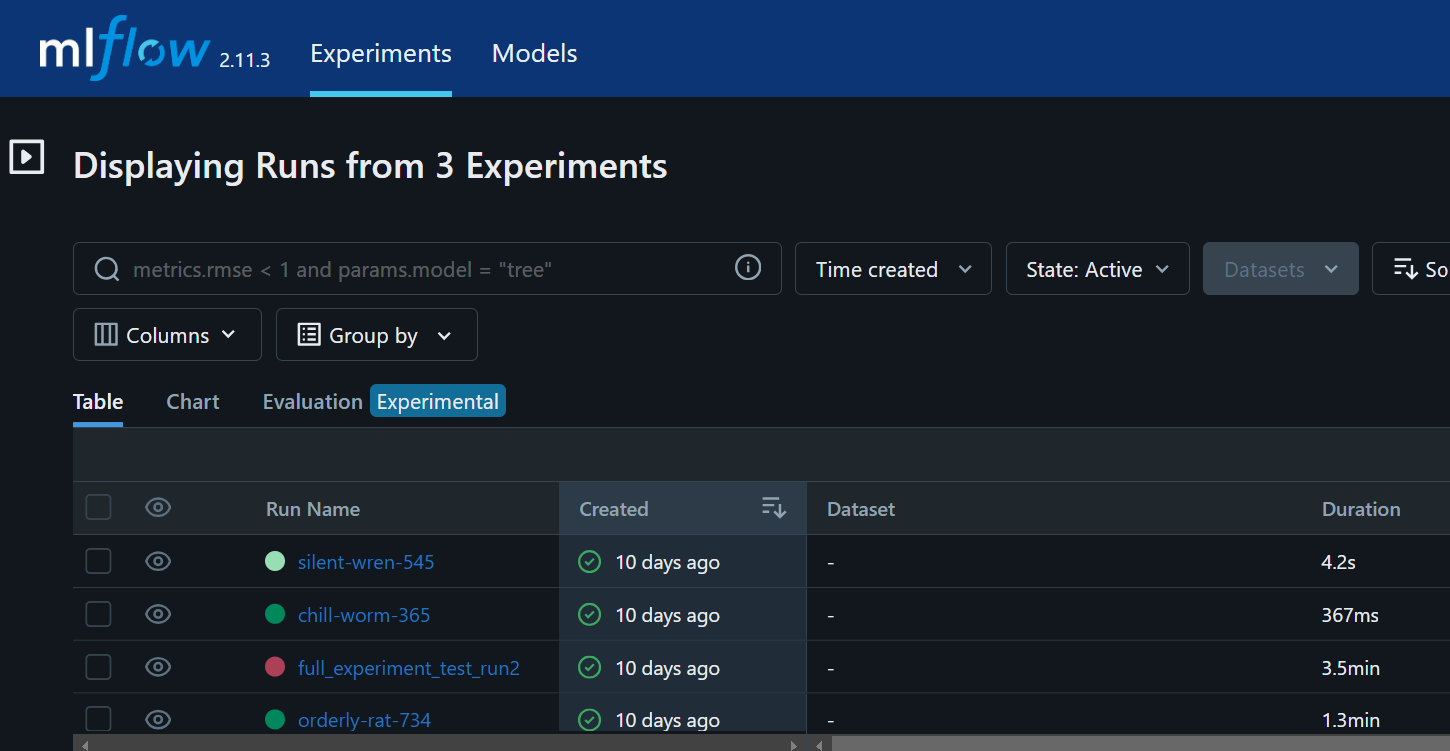
Skills: MLFlow, Experiment Design & Tracking, Computer Vision, Model Fine-tuning & Evaluation, Deep Learning, Documentation and reporting, Performance Benchmarking, Python
Evaluating SOTA Object Detection Models
In this project, I compared the YOLOv8 and RT-DETR models for detecting traffic and road signs using a dataset of 10,000 images. The dataset, sourced from Roboflow, was split into 7,092 training images, 1,884 validation images, and 1,024 test images. YOLOv8's performance improved across different configurations, achieving a maximum mAP of 0.2388 with 64 epochs and a batch size of 16. In contrast, RT-DETR, with its highest mAP of 0.2012 using the same number of epochs but a batch size of 16, showed less improvement
I used MLflow to track the performance of both models, recording metrics such as mAP, precision, recall, and inference time. YOLOv8 consistently outperformed RT-DETR in terms of detection accuracy and recall. The results will be further analyzed in future work to refine hyperparameter tuning and assess real-world inference performance, including speed and efficiency.
learn more
Skills: ETL, Google Cloud Platform, BigQuery, Python, Pub/Sub, Cloud Functions, API Integration, Data Transformation
Qualtrics to BigQuery: Automated ETL Pipeline
This project automates the ETL process for transferring survey data from Qualtrics to Google BigQuery. I used the Qualtrics API to extract raw survey data, which I then cleaned and transformed using a Python script. This script runs within a Google Cloud Function, triggered by messages published to Google Cloud Pub/Sub and scheduled via a CRON job to execute every 3 days. The cleaned data is automatically uploaded to BigQuery. By implementing this pipeline, I streamlined data processing and eliminated manual handling using Google Cloud services. The repository contains demo code, as the actual code cannot be shared due to privacy constraints.
learn more
Skills: NLP, Linguistic Analysis, Text Mining, Text Parsing, Data Visualization, R / RStudio, Python
Information extraction using NLP
I analyzed over 100,000 entries from the HappyDB dataset, a crowd-sourced collection of happy moments gathered via Amazon Mechanical Turk, to identify actions linked to happiness. Using spaCy's DependencyMatcher, I performed heuristic-based analysis of linguistic dependency trees to extract action phrases from the dataset. This process involved parsing textual data to isolate self-reported activities contributing to happiness. The results were visualized through word clouds and bar plots, capturing the frequency and nature of these actions despite the sparse distribution of contextual data.
learn more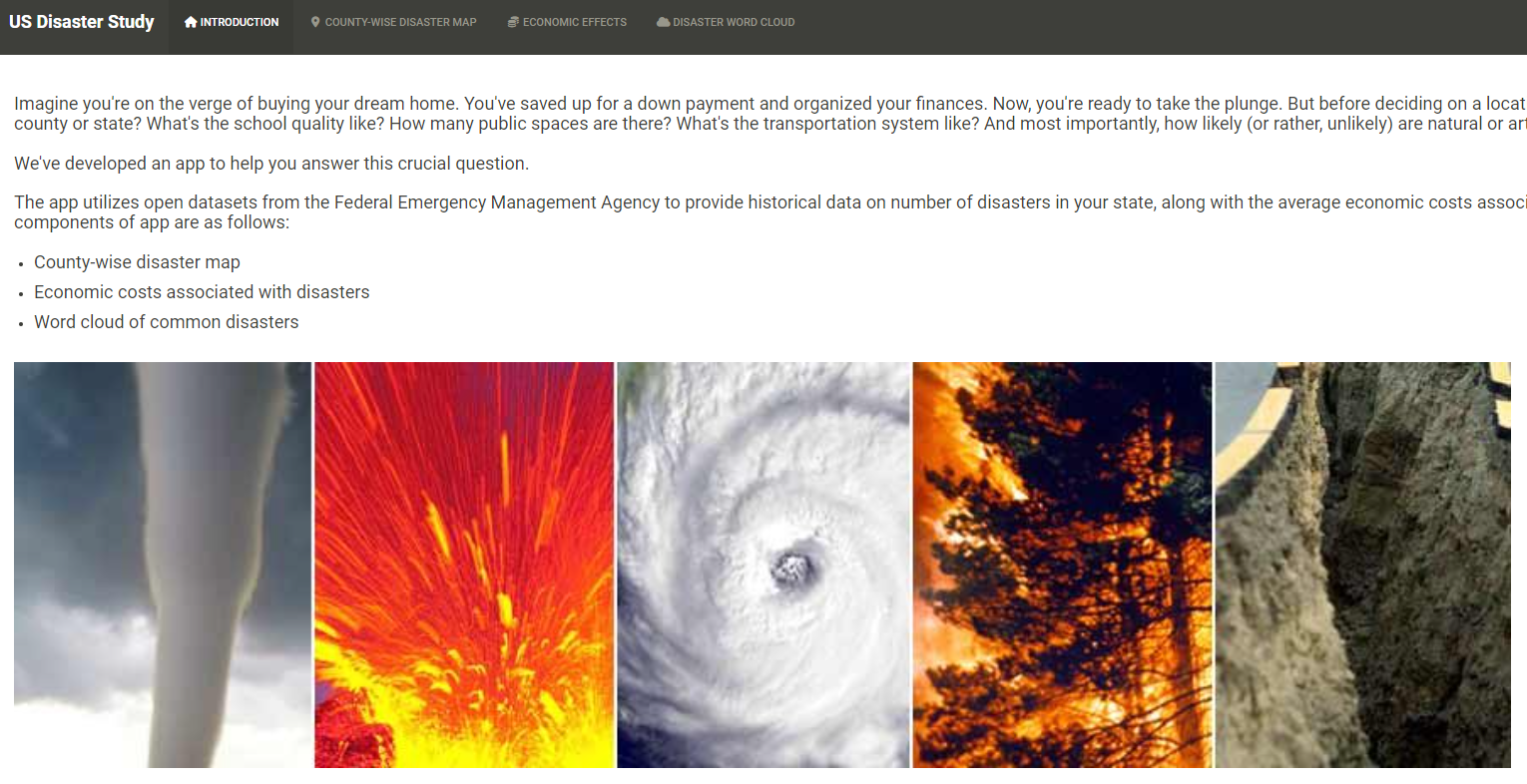
Skills: R-Shiny, SQL, PostgreSQL, Geospatial Visualization, Exploratory Data Analysis, Data Visualization, Web Development using RShiny
Interactive Geospatial Disaster Visualizations
In this project, my team and I built an interactive web application using R-Shiny to analyze and visualize disaster recurrence in the United States. We queried approximately 540,000 data points from the FEMA database using complex SQL queries in PostgreSQL, which involved aggregating disaster counts, assessing economic impacts, and categorizing disaster types.
The application features a geospatial map displaying disaster counts by county and year, a bar plot visualizing disaster categories and associated economic costs, and a word cloud representing the frequency of common disasters in selected areas. This tool offers comprehensive insights into disaster risks and economic impacts, helping prospective home buyers make informed decisions.
learn more
Skills: Machine Learning, Fairness Algorithms, Logistic Regression
Evaluating Machine Learning Fairness
[research paper implementation] My team and I analyzed the ProPublica COMPAS dataset, which uses logistic regression to predict reoffending risk but reveals biases affecting various social groups. We implemented and evaluated fairness algorithms from Zafar et al. (2017) "Fairness beyond disparate treatment & disparate impact" and Žliobaite et al. (2011) "Handling conditional discrimination" to mitigate these biases while maintaining prediction accuracy. Our work involved analysis and testing of these algorithms to assess their effectiveness in reducing unfairness in the model's predictions.
learn more
Skills: High-dimensional Clustering, Latent Class Models, Spectral Analysis, K-means Clustering
Initial implementation of DH-LCM
[research paper implementation] In this project, I applied the Degree-Heterogeneous Latent Class Model (DH-LCM), as proposed by Lyu et al. (2024), to a real-world dataset, specifically the Kaggle 'Patient Risk Profiles' dataset. The DH-LCM addresses the challenges of clustering high-dimensional binary data by leveraging a spectral approach to decompose the data. The algorithm was implemented by applying HeteroPCA to extract top singular vectors, normalizing principal components, and performing K-means clustering on the normalized vectors. The dataset, containing binary risk factors for heart failure, was resampled to meet specific assumptions of balanced cluster sizes and constant degrees. This work is a preliminary effort and is not yet validated for the model's efficacy.
learn more
Skills: Collaborative Filtering, Content-Based Filtering, Cosine Similarity, Word2Vec
Book Recommendation System
[preliminary stage] In this project, we implemented a book recommendation system using Collaborative Filtering and Content-Based Filtering techniques. For Collaborative Filtering, we used cosine similarity to recommend books based on user interactions, identifying similar users to provide tailored suggestions. For Content-Based Filtering, we employed word2vec to analyze book features and user preferences, generating recommendations based on the semantic similarity of book descriptions. We developed a user-friendly Shiny app interface, allowing users to input a book title and receive personalized recommendations from both methods. The app integrates with a recommendation engine built using Python and R, leveraging cosine similarity and word2vec for suggestions.
learn more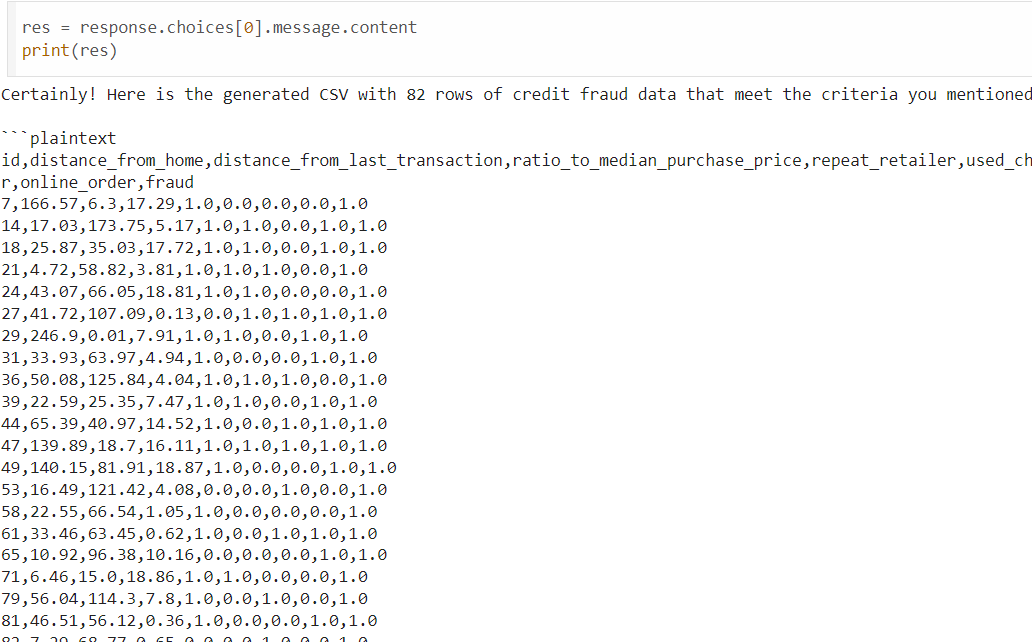
Skills: OpenAI API, Exploratory Data Analysis, Jupyter Notebook, Imbalanced Data Handling
Synthetic Data Generation for Imbalanced Data
[preliminary stage] In this project, I used OpenAI's chat completion feature to generate synthetic credit fraud data, aimed at addressing class imbalance issues in datasets. By leveraging the OpenAI API, I created a CSV file with 82 rows of synthetic data, focusing on fraudulent transactions. The dataset includes continuous variables, generated to follow deterministic statistical distributions with parameters like mean, standard deviation, and range.
This work was conducted as an exploratory analysis in a Jupyter Notebook environment, allowing for iterative adjustments and validation of the synthetic data's accuracy and relevance.
learn more